Understanding Query Execution with the Analyzer
ClickHouse processes queries extremely quickly, but the execution of a query is not a simple story. Let’s try to understand how a SELECT query gets executed. To illustrate it, let’s add some data in a table in ClickHouse:
CREATE TABLE session_events(
clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type String
) ORDER BY (timestamp);
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000;
Now that we have some data in ClickHouse, we want to run some queries and understand their execution. The execution of a query is decomposed into many steps. Each step of the query execution can be analyzed and troubleshooted using the corresponding EXPLAIN query. These steps are summarized in the chart below:
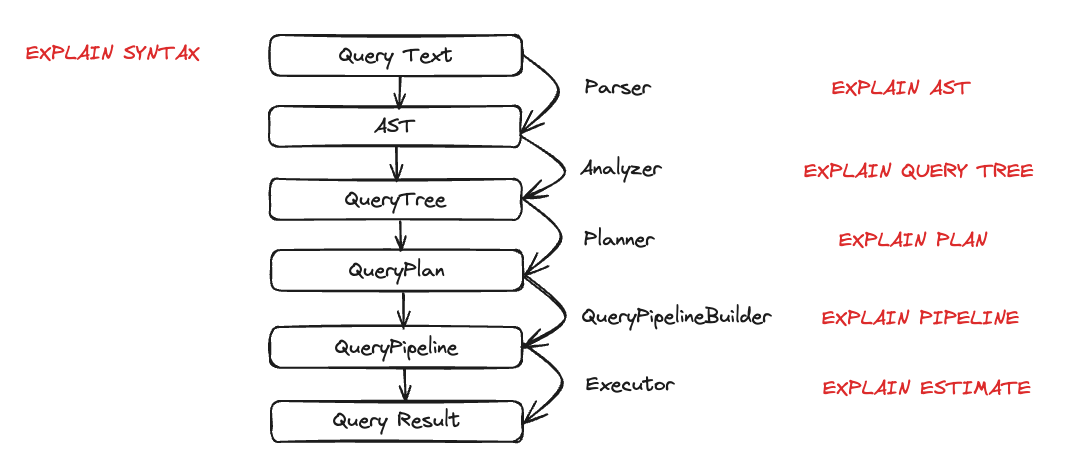
Let’s look at each entity in action during query execution. We are going to take a few queries and then examine them using the EXPLAIN statement.
Parser
The goal of a parser is to transform the query text into an AST (Abstract Syntax Tree). This step can be visualized using EXPLAIN AST:
EXPLAIN AST SELECT min(timestamp), max(timestamp) FROM session_events;
┌─explain────────────────────────────────────────────┐
│ SelectWithUnionQuery (children 1) │
│ ExpressionList (children 1) │
│ SelectQuery (children 2) │
│ ExpressionList (children 2) │
│ Function min (alias minimum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ Function max (alias maximum_date) (children 1) │
│ ExpressionList (children 1) │
│ Identifier timestamp │
│ TablesInSelectQuery (children 1) │
│ TablesInSelectQueryElement (children 1) │
│ TableExpression (children 1) │
│ TableIdentifier session_events │
└────────────────────────────────────────────────────┘
The output is an Abstract Syntax Tree that can be visualized as shown below:
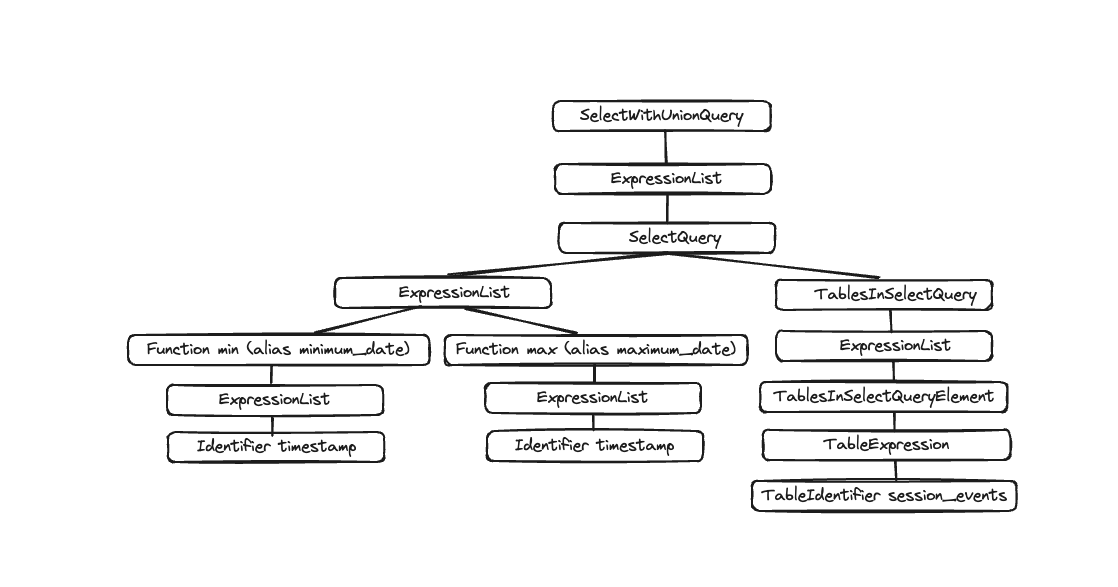
Each node has corresponding children and the overall tree represents the overall structure of your query. This is a logical structure to help processing a query. From an end-user standpoint (unless interested in query execution), it is not super useful; this tool is mainly used by developers.
Analyzer
ClickHouse currently has two architectures for the Analyzer. You can use the old architecture by setting: allow_experimental_analyzer=0. If you want to use the new architecture, you should set allow_experimental_analyzer=1. We are going to describe only the new architecture here, given the old one is going to be deprecated once the new analyzer is generally available.
The new analyzer is in Beta. The new architecture should provide us with a better framework to improve ClickHouse's performance. However, given it is a fundamental component of the query processing steps, it also might have a negative impact on some queries. After moving to the new analyzer, you may see performance degradation, queries failing, or queries giving you an unexpected result. You can revert back to the old analyzer by changing the allow_experimental_analyzer setting at the query or user level. Please report any issues in GitHub.
The analyzer is an important step of the query execution. It takes an AST and transforms it into a query tree. The main benefit of a query tree over an AST is that a lot of the components will be resolved, like the storage for instance. We also know from which table to read, aliases are also resolved, and the tree knows the different data types used. With all these benefits, the analyzer can apply optimizations. The way these optimizations work is via “passes”. Every pass is going to look for different optimizations. You can see all the passes here, let’s see it in practice with our previous query:
EXPLAIN QUERY TREE passes=0 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, alias: minimum_date, function_name: min, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ IDENTIFIER id: 4, identifier: timestamp │
│ FUNCTION id: 5, alias: maximum_date, function_name: max, function_type: ordinary │
│ ARGUMENTS │
│ LIST id: 6, nodes: 1 │
│ IDENTIFIER id: 7, identifier: timestamp │
│ JOIN TREE │
│ IDENTIFIER id: 8, identifier: session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└────────────────────────────────────────────────────────────────────────────────────────┘
EXPLAIN QUERY TREE passes=20 SELECT min(timestamp) AS minimum_date, max(timestamp) AS maximum_date FROM session_events SETTINGS allow_experimental_analyzer=1;
┌─explain───────────────────────────────────────────────────────────────────────────────────┐
│ QUERY id: 0 │
│ PROJECTION COLUMNS │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ PROJECTION │
│ LIST id: 1, nodes: 2 │
│ FUNCTION id: 2, function_name: min, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 3, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ FUNCTION id: 6, function_name: max, function_type: aggregate, result_type: DateTime │
│ ARGUMENTS │
│ LIST id: 7, nodes: 1 │
│ COLUMN id: 4, column_name: timestamp, result_type: DateTime, source_id: 5 │
│ JOIN TREE │
│ TABLE id: 5, alias: __table1, table_name: default.session_events │
│ SETTINGS allow_experimental_analyzer=1 │
└───────────────────────────────────────────────────────────────────────────────────────────┘
Between the two executions, you can see the resolution of aliases and projections.
Planner
The planner takes a query tree and builds a query plan out of it. The query tree tells us what we want to do with a specific query, and the query plan tells us how we will do it. Additional optimizations are going to be done as part of the query plan. You can use EXPLAIN PLAN or EXPLAIN to see the query plan (EXPLAIN will execute EXPLAIN PLAN).
EXPLAIN PLAN WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ ReadFromMergeTree (default.session_events) │
└──────────────────────────────────────────────────┘
Even though this is giving us some information, we can get more. For example, maybe we want to know the column's name on top of which we need the projections. You can add the header to the query:
EXPLAIN header = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain──────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Header: type String │
│ minimum_date DateTime │
│ maximum_date DateTime │
│ percentage Nullable(Float64) │
│ Aggregating │
│ Header: type String │
│ min(timestamp) DateTime │
│ max(timestamp) DateTime │
│ count() UInt64 │
│ Expression (Before GROUP BY) │
│ Header: timestamp DateTime │
│ type String │
│ ReadFromMergeTree (default.session_events) │
│ Header: timestamp DateTime │
│ type String │
└──────────────────────────────────────────────────┘
So now you know the column names that need to be created for the last Projection (minimum_date, maximum_date and percentage), but you might also want to have the details of all the actions that need to be executed. You can do so by setting actions=1.
EXPLAIN actions = 1
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
┌─explain────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Actions: INPUT :: 0 -> type String : 0 │
│ INPUT : 1 -> min(timestamp) DateTime : 1 │
│ INPUT : 2 -> max(timestamp) DateTime : 2 │
│ INPUT : 3 -> count() UInt64 : 3 │
│ COLUMN Const(Nullable(UInt64)) -> total_rows Nullable(UInt64) : 4 │
│ COLUMN Const(UInt8) -> 100 UInt8 : 5 │
│ ALIAS min(timestamp) :: 1 -> minimum_date DateTime : 6 │
│ ALIAS max(timestamp) :: 2 -> maximum_date DateTime : 1 │
│ FUNCTION divide(count() :: 3, total_rows :: 4) -> divide(count(), total_rows) Nullable(Float64) : 2 │
│ FUNCTION multiply(divide(count(), total_rows) :: 2, 100 :: 5) -> multiply(divide(count(), total_rows), 100) Nullable(Float64) : 4 │
│ ALIAS multiply(divide(count(), total_rows), 100) :: 4 -> percentage Nullable(Float64) : 5 │
│ Positions: 0 6 1 5 │
│ Aggregating │
│ Keys: type │
│ Aggregates: │
│ min(timestamp) │
│ Function: min(DateTime) → DateTime │
│ Arguments: timestamp │
│ max(timestamp) │
│ Function: max(DateTime) → DateTime │
│ Arguments: timestamp │
│ count() │
│ Function: count() → UInt64 │
│ Arguments: none │
│ Skip merging: 0 │
│ Expression (Before GROUP BY) │
│ Actions: INPUT :: 0 -> timestamp DateTime : 0 │
│ INPUT :: 1 -> type String : 1 │
│ Positions: 0 1 │
│ ReadFromMergeTree (default.session_events) │
│ ReadType: Default │
│ Parts: 1 │
│ Granules: 1 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
You can now see all the inputs, functions, aliases, and data types that are being used. You can see some of the optimizations that the planner is going to apply here.
Query Pipeline
A query pipeline is generated from the query plan. The query pipeline is very similar to the query plan, with the difference that it’s not a tree but a graph. It highlights how ClickHouse is going to execute a query and what resources are going to be used. Analyzing the query pipeline is very useful to see where the bottleneck is in terms of inputs/outputs. Let’s take our previous query and look at the query pipeline execution:
EXPLAIN PIPELINE
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type;
┌─explain────────────────────────────────────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform × 2 │
│ (Aggregating) │
│ Resize 1 → 2 │
│ AggregatingTransform │
│ (Expression) │
│ ExpressionTransform │
│ (ReadFromMergeTree) │
│ MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread) 0 → 1 │
└────────────────────────────────────────────────────────────────────────────┘
Inside the parenthesis is the query plan step, and next to it the processor. This is great information, but given this is a graph, it would be nice to visualize it as such. We have a setting graph we can set to 1 and specify the output format to be TSV:
EXPLAIN PIPELINE graph=1 WITH
(
SELECT count(*)
FROM session_events
) AS total_rows
SELECT type, min(timestamp) AS minimum_date, max(timestamp) AS maximum_date, count(*) /total_rows * 100 AS percentage FROM session_events GROUP BY type FORMAT TSV;
digraph
{
rankdir="LR";
{ node [shape = rect]
subgraph cluster_0 {
label ="Expression";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n5 [label="ExpressionTransform × 2"];
}
}
subgraph cluster_1 {
label ="Aggregating";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n3 [label="AggregatingTransform"];
n4 [label="Resize"];
}
}
subgraph cluster_2 {
label ="Expression";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n2 [label="ExpressionTransform"];
}
}
subgraph cluster_3 {
label ="ReadFromMergeTree";
style=filled;
color=lightgrey;
node [style=filled,color=white];
{ rank = same;
n1 [label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
}
}
}
n3 -> n4 [label=""];
n4 -> n5 [label="× 2"];
n2 -> n3 [label=""];
n1 -> n2 [label=""];
}
You can then copy this output and paste it here and that will generate the following graph:
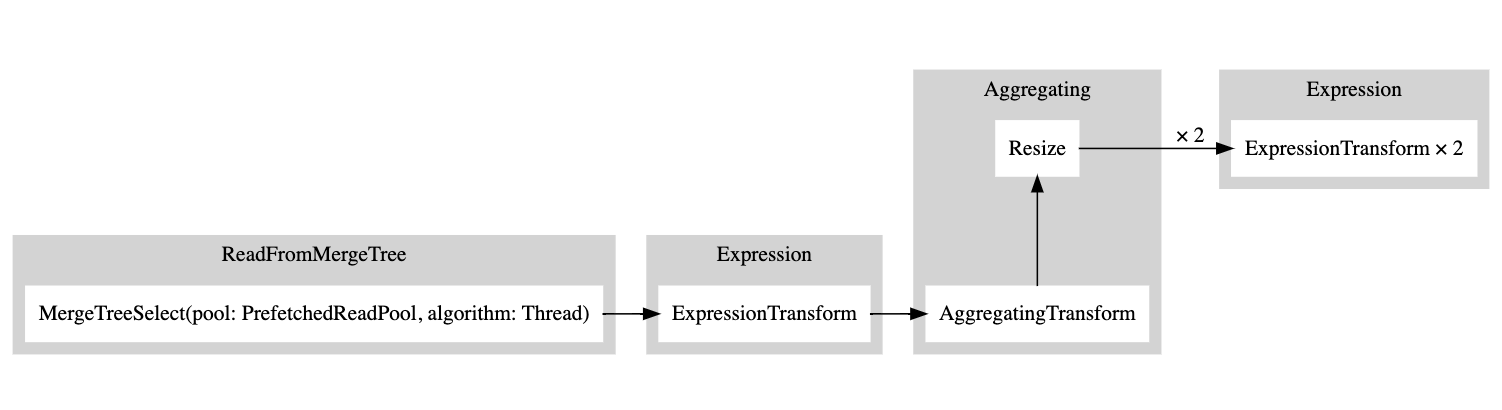
A white rectangle corresponds to a pipeline node, the gray rectangle corresponds to the query plan steps, and the x followed by a number corresponds to the number of inputs/outputs that are being used. If you do not want to see them in a compact form, you can always add compact=0:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="ExpressionTransform"];
n2[label="AggregatingTransform"];
n3[label="Resize"];
n4[label="ExpressionTransform"];
n5[label="ExpressionTransform"];
}
n0 -> n1;
n1 -> n2;
n2 -> n3;
n3 -> n4;
n3 -> n5;
}

Why does ClickHouse not read from the table using multiple threads? Let's try to add more data to our table:
INSERT INTO session_events SELECT * FROM generateRandom('clientId UUID,
sessionId UUID,
pageId UUID,
timestamp DateTime,
type Enum(\'type1\', \'type2\')', 1, 10, 2) LIMIT 1000000;
Now let's run our EXPLAIN query again:
EXPLAIN PIPELINE graph = 1, compact = 0
WITH (
SELECT count(*)
FROM session_events
) AS total_rows
SELECT
type,
min(timestamp) AS minimum_date,
max(timestamp) AS maximum_date,
(count(*) / total_rows) * 100 AS percentage
FROM session_events
GROUP BY type
FORMAT TSV
digraph
{
rankdir="LR";
{ node [shape = rect]
n0[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n1[label="MergeTreeSelect(pool: PrefetchedReadPool, algorithm: Thread)"];
n2[label="ExpressionTransform"];
n3[label="ExpressionTransform"];
n4[label="StrictResize"];
n5[label="AggregatingTransform"];
n6[label="AggregatingTransform"];
n7[label="Resize"];
n8[label="ExpressionTransform"];
n9[label="ExpressionTransform"];
}
n0 -> n2;
n1 -> n3;
n2 -> n4;
n3 -> n4;
n4 -> n5;
n4 -> n6;
n5 -> n7;
n6 -> n7;
n7 -> n8;
n7 -> n9;
}

So the executor decided not to parallelize operations because the volume of data was not high enough. By adding more rows, the executor then decided to use multiple threads as shown in the graph.
Executor
Finally the last step of the query execution is done by the executor. It will take the query pipeline and execute it. There are different types of executors, depending if you are doing a SELECT, an INSERT, or an INSERT SELECT.