ClickHouse Kafka Connect Sink
If you need any help, please file an issue in the repository or raise a question in ClickHouse public Slack.
ClickHouse Kafka Connect Sink is the Kafka connector delivering data from a Kafka topic to a ClickHouse table.
License
The Kafka Connector Sink is distributed under the Apache 2.0 License
Requirements for the environment
The Kafka Connect framework v2.7 or later should be installed in the environment.
Version compatibility matrix
| ClickHouse Kafka Connect version | ClickHouse version | Kafka Connect | Confluent platform |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
Main Features
- Shipped with out-of-the-box exactly-once semantics. It's powered by a new ClickHouse core feature named KeeperMap (used as a state store by the connector) and allows for minimalistic architecture.
- Support for 3rd-party state stores: Currently defaults to In-memory but can use KeeperMap (Redis to be added soon).
- Core integration: Built, maintained, and supported by ClickHouse.
- Tested continuously against ClickHouse Cloud.
- Data inserts with a declared schema and schemaless.
- Support for all data types of ClickHouse.
Installation instructions
Gather your connection details
To connect to ClickHouse with HTTP(S) you need this information:
The HOST and PORT: typically, the port is 8443 when using TLS or 8123 when not using TLS.
The DATABASE NAME: out of the box, there is a database named
default, use the name of the database that you want to connect to.The USERNAME and PASSWORD: out of the box, the username is
default. Use the username appropriate for your use case.
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select the service that you will connect to and click Connect:
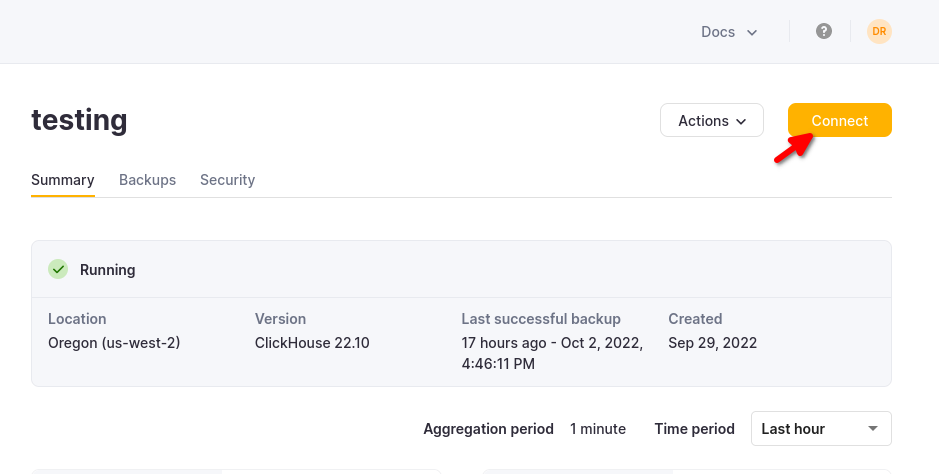
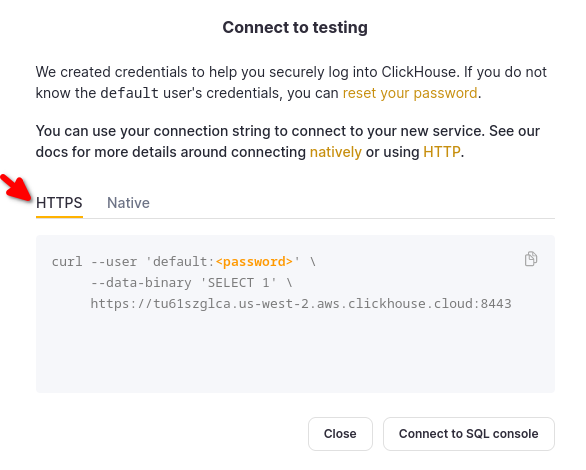
Choose HTTPS, and the details are available in an example curl command.
If you are using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
General Installation Instructions
The connector is distributed as a single uber JAR file containing all the class files necessary to run the plugin.
To install the plugin, follow these steps:
- Download a zip archive containing the Connector JAR file from the Releases page of ClickHouse Kafka Connect Sink repository.
- Extract the ZIP file content and copy it to the desired location.
- Add a path with the plugin director to plugin.path configuration in your Connect properties file to allow Confluent Platform to find the plugin.
- Provide a topic name, ClickHouse instance hostname, and password in config.
connector.class=com.clickhouse.kafka.connect.ClickHouseSinkConnector
tasks.max=1
topics=<topic_name>
ssl=true
jdbcConnectionProperties=?sslmode=STRICT
security.protocol=SSL
hostname=<hostname>
database=<database_name>
password=<password>
ssl.truststore.location=/tmp/kafka.client.truststore.jks
port=8443
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
exactlyOnce=true
username=default
schemas.enable=false
- Restart the Confluent Platform.
- If you use Confluent Platform, log into Confluent Control Center UI to verify the ClickHouse Sink is available in the list of available connectors.
Configuration options
To connect the ClickHouse Sink to the ClickHouse server, you need to provide:
- connection details: hostname (required) and port (optional)
- user credentials: password (required) and username (optional)
- connector class:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(required) - topics or topics.regex: the Kafka topics to poll - topic names must match table names (required)
- key and value converters: set based on the type of data on your topic. Required if not already defined in worker config.
The full table of configuration options:
| Property Name | Description | Default Value |
|---|---|---|
hostname (Required) | The hostname or IP address of the server | N/A |
port | The ClickHouse port - default is 8443 (for HTTPS in the cloud), but for HTTP (the default for self-hosted) it should be 8123 | 8443 |
ssl | Enable ssl connection to ClickHouse | true |
jdbcConnectionProperties | Connection properties when connecting to Clickhouse. Must start with ? and joined by & between param=value | "" |
username | ClickHouse database username | default |
password (Required) | ClickHouse database password | N/A |
database | ClickHouse database name | default |
connector.class (Required) | Connector Class(explicit set and keep as the default value) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | The number of Connector Tasks | "1" |
errors.retry.timeout | ClickHouse JDBC Retry Timeout | "60" |
exactlyOnce | Exactly Once Enabled | "false" |
topics (Required) | The Kafka topics to poll - topic names must match table names | "" |
key.converter (Required* - See Description) | Set according to the types of your keys. Required here if you are passing keys (and not defined in worker config). | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (Required* - See Description) | Set based on the type of data on your topic. Supported: - JSON, String, Avro or Protobuf formats. Required here if not defined in worker config. | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | Connector Value Converter Schema Support | "false" |
errors.tolerance | Connector Error Tolerance. Supported: none, all | "none" |
errors.deadletterqueue.topic.name | If set (with errors.tolerance=all), a DLQ will be used for failed batches (see Troubleshooting) | "" |
errors.deadletterqueue.context.headers.enable | Adds additional headers for the DLQ | "" |
clickhouseSettings | Comma-separated list of ClickHouse settings (e.g. "insert_quorum=2, etc...") | "" |
topic2TableMap | Comma-separated list that maps topic names to table names (e.g. "topic1=table1, topic2=table2, etc...") | "" |
tableRefreshInterval | Time (in seconds) to refresh the table definition cache | 0 |
keeperOnCluster | Allows configuration of ON CLUSTER parameter for self-hosted instances (e.g. " ON CLUSTER clusterNameInConfigFileDefinition ") for exactly-once connect_state table (see Distributed DDL Queries | "" |
bypassRowBinary | Allows disabling use of RowBinary and RowBinaryWithDefaults for Schema-based data (Avro, Protobuf, etc.) - should only be used when data will have missing columns, and Nullable/Default are unacceptable | "false" |
dateTimeFormats | Date time formats for parsing DateTime64 schema fields, seperated by ; (e.g. 'someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss'). | "" |
Target Tables
ClickHouse Connect Sink reads messages from Kafka topics and writes them to appropriate tables. ClickHouse Connect Sink writes data into existing tables. Please, make sure a target table with an appropriate schema was created in ClickHouse before starting to insert data into it.
Each topic requires a dedicated target table in ClickHouse. The target table name must match the source topic name.
Pre-processing
If you need to transform outbound messages before they are sent to ClickHouse Kafka Connect Sink, use Kafka Connect Transformations.
Supported Data types
With a schema declared:
| Kafka Connect Type | ClickHouse Type | Supported | Primitive |
|---|---|---|---|
| STRING | String | ✅ | Yes |
| INT8 | Int8 | ✅ | Yes |
| INT16 | Int16 | ✅ | Yes |
| INT32 | Int32 | ✅ | Yes |
| INT64 | Int64 | ✅ | Yes |
| FLOAT32 | Float32 | ✅ | Yes |
| FLOAT64 | Float64 | ✅ | Yes |
| BOOLEAN | Boolean | ✅ | Yes |
| ARRAY | Array(T) | ✅ | No |
| MAP | Map(Primitive, T) | ✅ | No |
| STRUCT | Variant(T1, T2, …) | ✅ | No |
| STRUCT | Tuple(a T1, b T2, …) | ✅ | No |
| STRUCT | Nested(a T1, b T2, …) | ✅ | No |
| BYTES | String | ✅ | No |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | No |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | No |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | No |
Without a schema declared:
A record is converted into JSON and sent to ClickHouse as a value in JSONEachRow format.
Configuration Recipes
These are some common configuration recipes to get you started quickly.
Basic Configuration
The most basic configuration to get you started - it assumes you're running Kafka Connect in distributed mode and have a ClickHouse server running on localhost:8443 with SSL enabled, data is in schemaless JSON.
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
"tasks.max": "1",
"consumer.override.max.poll.records": "5000",
"consumer.override.max.partition.fetch.bytes": "5242880",
"database": "default",
"errors.retry.timeout": "60",
"exactlyOnce": "false",
"hostname": "localhost",
"port": "8443",
"ssl": "true",
"jdbcConnectionProperties": "?ssl=true&sslmode=strict",
"username": "default",
"password": "<PASSWORD>",
"topics": "<TOPIC_NAME>",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"clickhouseSettings": ""
}
}
Basic Configuration with Multiple Topics
The connector can consume data from multiple topics
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"topics": "SAMPLE_TOPIC, ANOTHER_TOPIC, YET_ANOTHER_TOPIC",
...
}
}
Basic Configuration with DLQ
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "<DLQ_TOPIC>",
"errors.deadletterqueue.context.headers.enable": "true",
}
}
Using with different data formats
Avro Schema Support
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
Protobuf Schema Support
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "io.confluent.connect.protobuf.ProtobufConverter",
"value.converter.schema.registry.url": "<SCHEMA_REGISTRY_HOST>:<PORT>",
"value.converter.schemas.enable": "true",
}
}
Please note: if you encounter issues with missing classes, not every environment comes with the protobuf converter and you may need an alternate release of the jar bundled with dependencies.
JSON Schema Support
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
}
}
String Support
The connector supports the String Converter in different ClickHouse formats: JSON, CSV, and TSV.
{
"name": "clickhouse-connect",
"config": {
"connector.class": "com.clickhouse.kafka.connect.ClickHouseSinkConnector",
...
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"customInsertFormat": "true",
"insertFormat": "CSV"
}
}
Logging
Logging is automatically provided by Kafka Connect Platform. The logging destination and format might be configured via Kafka connect configuration file.
If using the Confluent Platform, the logs can be seen by running a CLI command:
confluent local services connect log
For additional details check out the official tutorial.
Monitoring
ClickHouse Kafka Connect reports runtime metrics via Java Management Extensions (JMX). JMX is enabled in Kafka Connector by default.
ClickHouse Connect MBeanName:
com.clickhouse:type=ClickHouseKafkaConnector,name=SinkTask{id}
ClickHouse Kafka Connect reports the following metrics:
| Name | Type | Description |
|---|---|---|
| receivedRecords | long | The total number of records received. |
| recordProcessingTime | long | Total time in nanoseconds spent grouping and converting records to a unified structure. |
| taskProcessingTime | long | Total time in nanoseconds spent processing and inserting data into ClickHouse. |
Limitations
- Deletes are not supported.
- Batch size is inherited from the Kafka Consumer properties.
- When using KeeperMap for exactly-once and the offset is changed or re-wound, you need to delete the content from KeeperMap for that specific topic. (See troubleshooting guide below for more details)
Tuning Performance
If you've ever though to yourself "I would like to adjust the batch size for the sink connector", then this is the section for you.
Connect Fetch vs Connector Poll
Kafka Connect (the framework our sink connector is built on) will fetch messages from kafka topics in the background (independent of the connector).
You can control this process using fetch.min.bytes and fetch.max.bytes - while fetch.min.bytes sets the minimum amount required before the framework will pass values to the connector (up to a time limit set by fetch.max.wait.ms), fetch.max.bytes sets the upper size limit. If you wanted to pass larger batches to the connector, an option could be to increase the minimum fetch or maximum wait to build bigger data bundles.
This fetched data is then consumed by the connector client polling for messages, where the amount for each poll is controlled by max.poll.records - please note that fetch is independent of poll, though!
When tuning these settings, users should aim so their fetch size produces multiple batches of max.poll.records (and keep in mind, the settings fetch.min.bytes and fetch.max.bytes represent compressed data) - that way, each connector task is inserting as large a batch as possible.
ClickHouse is optimized for larger batches, even at a slight delay, rather than frequent but smaller batches - the larger the batch, the better.
consumer.max.poll.records=5000
consumer.max.partition.fetch.bytes=5242880
More details can be found in the Confluent documentation or in the Kafka documentation.
Multiple high throughput topics
If your connector is configured to subscribe to mutliple topics, you're using topics2TableMap to map topics to tables, and you're experiencing a bottleneck at insertion resulting in consumer lag, consider creating one connector per topic instead. The main reason why this happens is that currently batches are inserted into every table serially.
Creating one connector per topic is a workaround that ensures that you get the fastest possible insert rate.
Troubleshooting
"State mismatch for topic [someTopic] partition [0]"
This happens when the offset stored in KeeperMap is different from the offset stored in Kafka, usually when a topic has been deleted or the offset has been manually adjusted. To fix this, you would need to delete the old values stored for that given topic + partition.
NOTE: This adjustment may have exactly-once implications.
"What errors will the connector retry?"
Right now the focus is on identifying errors that are transient and can be retried, including:
ClickHouseException- This is a generic exception that can be thrown by ClickHouse. It is usually thrown when the server is overloaded and the following error codes are considered particularly transient:- 3 - UNEXPECTED_END_OF_FILE
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
- 1002 - UNKNOWN_EXCEPTION
SocketTimeoutException- This is thrown when the socket times out.UnknownHostException- This is thrown when the host cannot be resolved.IOException- This is thrown when there is a problem with the network.
"All my data is blank/zeroes"
Likely the fields in your data don't match the fields in the table - this is especially common with CDC (and the Debezium format). One common solution is to add the flatten transformation to your connector configuration:
transforms=flatten
transforms.flatten.type=org.apache.kafka.connect.transforms.Flatten$Value
transforms.flatten.delimiter=_
This will transform your data from a nested JSON to a flattened JSON (using _ as a delimiter). Fields in the table would then follow the "field1_field2_field3" format (i.e. "before_id", "after_id", etc.).
"I want to use my Kafka keys in ClickHouse"
Kafka keys are not stored in the value field by default, but you can use the KeyToValue transformation to move the key to the value field (under a new _key field name):
transforms=keyToValue
transforms.keyToValue.type=com.clickhouse.kafka.connect.transforms.KeyToValue
transforms.keyToValue.field=_key